Daniel CraciunStop Using UUIDv4 in Your DatabaseHow UUIDs can Destroy SQL Database PerformanceMay 16, 202493May 16, 202493
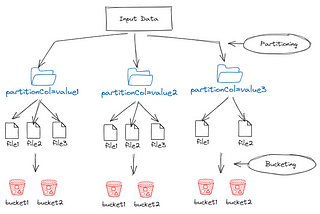
InData Engineer ThingsbyKerrache MassipssaApache Spark Partitioning and BucketingLearn the Partitioning and Bucketing with Apache Spark (PySpark) and understand how and when to use each of them.Dec 14, 20232Dec 14, 20232
Shruti GhoradkarSpark Scenario-Based Interview Questions Part II.link of part I: https://medium.com/me/stats/post/1fd3485c2911Feb 4, 2024Feb 4, 2024
Vengateswaran ArunachalamMastering Spark Memory Allocation for 1 Billion RowsProcessing big data efficiently in Spark is an art. Here’s how you can estimate the memory needed for processing a 1 billion row table with…Nov 14, 20232Nov 14, 20232
InTowards Data MeshbyAmine Kaabachi2023 — Rockstar Data Engineer RoadmapThis article presents a roadmap for those who want to become Data Engineers in 2023. It also serves as a reference to learn and improve…Jan 1, 20233Jan 1, 20233
InTDS Archiveby💡Mike ShakhomirovData pipeline design patternsChoosing the right architecture with examplesJan 2, 20238Jan 2, 20238